
Bo Jackson and present-day stars get the Tecmo treatment for what is likely to be a highly coveted set of cards.

Bend, Oregon


Most upcycling projects ask you to forget what something used to be. Omri Piko Kahan’s bike frame chairs ask the opposite. The geometry is still unmistakably a bicycle frame, the head tube, the top tube, the triangulated rear triangle, all of it present and accounted for, just oriented sideways and asked to hold a person instead of propel one. Kahan, an industrial designer based in Israel, builds lounge chairs from pairs of retired frames, and the whole point is that the donor material remains fully readable, repurposed without being disguised.
Structurally, the approach is clean and considered. Each frame pair is positioned symmetrically, fork and chainstay ends touching the floor as legs, the top tube running horizontally as an armrest. A slung seat and backrest in leather or canvas complete the form. The result has the relaxed posture of a Barcelona chair and the material honesty of something that was clearly built, not styled.
Designer: Omri Piko Kahan

Bicycle frames are absurdly overbuilt for what Kahan is asking them to do. A modern aluminum road frame is engineered to survive repeated impact loads from a rider pushing 300 watts through rough tarmac, and it does that while weighing somewhere between 1,000 and 1,400 grams. The structural surplus in that kind of engineering is enormous, which is why two of them positioned as a chair frame and asked to support a seated adult is, from a load-bearing standpoint, almost comically within spec. The geometry does the rest. Bicycle frames already resolve forces through triangulated sections, and a lounge chair asks for exactly that kind of lateral and compressive stability.


What Kahan has figured out is the orientation problem. Flip a frame on its side and the existing tube angles don’t automatically produce a useful chair geometry. The fork legs and chainstay ends need to hit the floor at the right height relative to each other, the top tube needs to land at armrest height, and the whole thing needs to produce a seat rake that doesn’t pitch you forward or swallow you whole. The matched top tube angles across both frames in the Cube and Trek build suggest this took real iteration, because they align with a precision that reads as deliberate rather than lucky. Filed fillets at the junctions and a custom setback upper support holding the sling confirm someone was paying close attention to finish quality.


The two builds photographed so far, one pairing a blue Cube road frame with a Trek, another combining a GT Transeo 3.0 with what appears to be a Supreme-branded MTB frame, show how much the donor bikes drive the final character of each piece. The GT build in particular has a longer wheelbase geometry that gives the chair a wider, more reclined stance than the Cube version. Kahan is taking custom orders, with pricing worked out per commission, which makes sense given that no two donor frame combinations will produce the same structural or ergonomic outcome.

The post These Old Bike Frames Upcycled Into Armchairs Are The Coolest Thing You’ll See Today first appeared on Yanko Design.
Bend, Oregon

My position on the urgency of rolling out quantum-resistant cryptography has changed compared to just a few months ago. You might have heard this privately from me in the past weeks, but it’s time to signal and justify this change of mind publicly.
There had been rumors for a while of expected and unexpected progress towards cryptographically-relevant quantum computers, but over the last week we got two public instances of it.
First, Google published a paper revising down dramatically the estimated number of logical qubits and gates required to break 256-bit elliptic curves like NIST P-256 and secp256k1, which makes the attack doable in minutes on fast-clock architectures like superconducting qubits. They weirdly1 frame it around cryptocurrencies and mempools and salvaged goods or something, but the far more important implication are practical WebPKI MitM attacks.
Shortly after, a different paper came out from Oratomic showing 256-bit elliptic curves can be broken in as few as 10,000 physical qubits if you have non-local connectivity, like neutral atoms seem to offer, thanks to better error correction. This attack would be slower, but even a single broken key per month can be catastrophic.
They have this excellent graph on page 2 (Babbush et al. is the Google paper, which they presumably had preview access to):
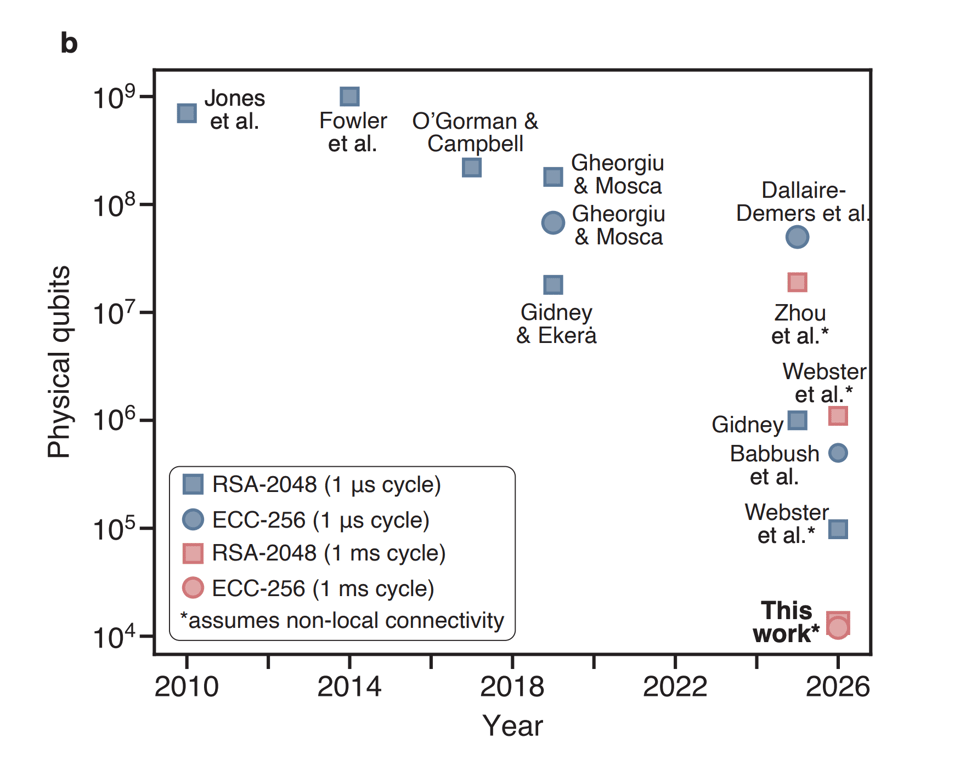
Overall, it looks like everything is moving: the hardware is getting better, the algorithms are getting cheaper, the requirements for error correction are getting lower.
I’ll be honest, I don’t actually know what all the physics in those papers means. That’s not my job and not my expertise. My job includes risk assessment on behalf of the users that entrusted me with their safety. What I know is what at least some actual experts are telling us.
Heather Adkins and Sophie Schmieg are telling us that “quantum frontiers may be closer than they appear” and that 2029 is their deadline. That’s in 33 months, and no one had set such an aggressive timeline until this month.
Scott Aaronson tells us that the “clearest warning that [he] can offer in public right now about the urgency of migrating to post-quantum cryptosystems” is a vague parallel with how nuclear fission research stopped happening in public between 1939 and 1940.
The timelines presented at RWPQC 2026, just a few weeks ago, were much tighter than a couple years ago, and are already partially obsolete. The joke used to be that quantum computers have been 10 years out for 30 years now. Well, not true anymore, the timelines have started progressing.
If you are thinking “well, this could be bad, or it could be nothing!” I need you to recognize how immediately dispositive that is. The bet is not “are you 100% sure a CRQC will exist in 2030?”, the bet is “are you 100% sure a CRQC will NOT exist in 2030?” I simply don’t see how a non-expert can look at what the experts are saying, and decide “I know better, there is in fact < 1% chance.” Remember that you are betting with your users’ lives.2
Put another way, even if the most likely outcome was no CRQC in our lifetimes, that would be completely irrelevant, because our users don’t want just better-than-even odds3 of being secure.
Sure, papers about an abacus and a dog are funny and can make you look smart and contrarian on forums. But that’s not the job, and those arguments betray a lack of expertise. As Scott Aaronson said:
Once you understand quantum fault-tolerance, asking “so when are you going to factor 35 with Shor’s algorithm?” becomes sort of like asking the Manhattan Project physicists in 1943, “so when are you going to produce at least a small nuclear explosion?”
The job is not to be skeptical of things we’re not experts in, the job is to mitigate credible threats, and there are credible experts that are telling us about an imminent threat.
In summary, it might be that in 10 years the predictions will turn out to be wrong, but at this point they might also be right soon, and that risk is now unacceptable.
Now what
Concretely, what does this mean? It means we need to ship.
Regrettably, we’ve got to roll out what we have.4 That means large ML-DSA signatures shoved in places designed for small ECDSA signatures, like X.509, with the exception of Merkle Tree Certificates for the WebPKI, which is thankfully far enough along.
This is not the article I wanted to write. I’ve had a pending draft for months now explaining we should ship PQ key exchange now, but take the time we still have to adapt protocols to larger signatures, because they were all designed with the assumption that signatures are cheap. That other article is now wrong, alas: we don’t have the time if we need to be finished by 2029 instead of 2035.
For key exchange, the migration to ML-KEM is going well enough but:
-
Any non-PQ key exchange should now be considered a potential active compromise, worthy of warning the user like OpenSSH does, because it’s very hard to make sure all secrets transmitted over the connection or encrypted in the file have a shorter shelf life than three years.
-
We need to forget about non-interactive key exchanges (NIKEs) for a while; we only have KEMs (which are only unidirectionally authenticated without interactivity) in the PQ toolkit.
It makes no more sense to deploy new schemes that are not post-quantum. I know, pairings were nice. I know, everything PQ is annoyingly large. I know, we had basically just figured out how to do ECDSA over P-256 safely. I know, there might not be practical PQ equivalents for threshold signatures or identity-based encryption. Trust me, I know it stings. But it is what it is.
Hybrid classic + post-quantum authentication makes no sense to me anymore and will only slow us down; we should go straight to pure ML-DSA-44.6 Hybrid key exchange is reasonably easy, with ephemeral keys that don’t even need a type or wire format for the composite private key, and a couple years ago it made sense to take the hedge. Authentication is not like that, and even with draft-ietf-lamps-pq-composite-sigs-15 with its 18 composite key types nearing publication, we’d waste precious time collectively figuring out how to treat these composite keys and how to expose them to users. It’s also been two years since Kyber hybrids and we’ve gained significant confidence in the Module-Lattice schemes. Hybrid signatures cost time and complexity budget,5 and the only benefit is protection if ML-DSA is classically broken before the CRQCs come, which looks like the wrong tradeoff at this point.
In symmetric encryption, we don’t need to do anything, thankfully. There is a common misconception that protection from Grover requires 256-bit keys, but that is based on an exceedingly simplified understanding of the algorithm. A more accurate characterization is that with a circuit depth of 2⁶⁴ logical gates (the approximate number of gates that current classical computing architectures can perform serially in a decade) running Grover on a 128-bit key space would require a circuit size of 2¹⁰⁶. There’s been no progress on this that I am aware of, and indeed there are old proofs that Grover is optimal and its quantum speedup doesn’t parallelize. Unnecessary 256-bit key requirements are harmful when bundled with the actually urgent PQ requirements, because they muddle the interoperability targets and they risk slowing down the rollout of asymmetric PQ cryptography.
In my corner of the world, we’ll have to start thinking about what it means for half the cryptography packages in the Go standard library to be suddenly insecure, and how to balance the risk of downgrade attacks and backwards compatibility. It’s the first time in our careers we’ve faced anything like this: SHA-1 to SHA-256 was not nearly this disruptive,7 and even that took forever with the occasional unexpected downgrade attack.
Trusted Execution Environments (TEEs) like Intel SGX and AMD SEV-SNP and in general hardware attestation are just f***d. All their keys and roots are not PQ and I heard of no progress in rolling out PQ ones, which at hardware speeds means we are forced to accept they might not make it, and can’t be relied upon. I had to reassess a whole project because of this, and I will probably downgrade them to barely “defense in depth” in my toolkit.
Ecosystems with cryptographic identities (like atproto and, yes, cryptocurrencies) need to start migrating very soon, because if the CRQCs come before they are done, they will have to make extremely hard decisions, picking between letting users be compromised and bricking them.
File encryption is especially vulnerable to store-now-decrypt-later attacks, so we’ll probably have to start warning and then erroring out on non-PQ age recipient types soon. It’s unfortunately only been a few months since we even added PQ recipients, in version 1.3.0.8
Finally, this week I started teaching a PhD course in cryptography at the University of Bologna, and I’m going to mention RSA, ECDSA, and ECDH only as legacy algorithms, because that’s how those students will encounter them in their careers. I know, it feels weird. But it is what it is.
For more willing-or-not PQ migration, follow me on Bluesky at @filippo.abyssdomain.expert or on Mastodon at @filippo@abyssdomain.expert.
The picture
Traveling back from an excellent AtmosphereConf 2026, I saw my first aurora, from the north-facing window of a Boeing 747.

My work is made possible by Geomys, an organization of professional Go maintainers, which is funded by Ava Labs, Teleport, Tailscale, and Sentry. Through our retainer contracts they ensure the sustainability and reliability of our open source maintenance work and get a direct line to my expertise and that of the other Geomys maintainers. (Learn more in the Geomys announcement.) Here are a few words from some of them!
Teleport — For the past five years, attacks and compromises have been shifting from traditional malware and security breaches to identifying and compromising valid user accounts and credentials with social engineering, credential theft, or phishing. Teleport Identity is designed to eliminate weak access patterns through access monitoring, minimize attack surface with access requests, and purge unused permissions via mandatory access reviews.
Ava Labs — We at Ava Labs, maintainer of AvalancheGo (the most widely used client for interacting with the Avalanche Network), believe the sustainable maintenance and development of open source cryptographic protocols is critical to the broad adoption of blockchain technology. We are proud to support this necessary and impactful work through our ongoing sponsorship of Filippo and his team.
-
The whole paper is a bit goofy: it has a zero-knowledge proof for a quantum circuit that will certainly be rederived and improved upon before the actual hardware to run it on will exist. They seem to believe this is about responsible disclosure, so I assume this is just physicists not being experts in our field in the same way we are not experts in theirs. ↩
-
“You” is doing a lot of work in this sentence, but the audience for this post is a bit unusual for me: I’m addressing my colleagues and the decision-makers that gate action on deployment of post-quantum cryptography. ↩
-
I had a reviewer object to an attacker probability of success of 1/536,870,912 (0.0000002%, 2⁻²⁹) after 2⁶⁴ work, correctly so, because in cryptography we usually target 2⁻³². ↩
-
Why trust the new stuff, though? There are two parts to it: the math and the implementation. The math is also not my job, so I again defer to experts like Sophie Schmieg, who tells us that she is very confident in lattices, and the NSA, who approved ML-KEM and ML-DSA at the Top Secret level for all national security purposes. It is also older than elliptic curve cryptography was when it first got deployed. (“Doesn’t the NSA lie to break our encryption?” No, the NSA has never intentionally jeopardized US national security with a non-NOBUS backdoor, and there is no way for ML-KEM and ML-DSA to hide a NOBUS backdoor.) On the implementation side, I am actually very qualified to have an opinion, having made cryptography implementation and testing my niche. ML-KEM and ML-DSA are a lot easier to implement securely than their classical alternatives, and with the better testing infrastructure we have now I expect to see exceedingly few bugs in their implementations. ↩
-
One small exception in that if you already have the ability to convey multiple signatures from multiple public keys in your protocol, it can make sense to to “poor man’s hybrid signatures” by just requiring 2-of-2 signatures from one classical public key and one pure PQ key. Some of the tlog ecosystem might pick this route, but that’s only because the cost is significantly lowered by the existing support for nested n-of-m signing groups. ↩
-
Why ML-DSA-44 when we usually use ML-KEM-768 instead of ML-KEM-512? Because ML-KEM-512 is Level 1, while ML-DSA-44 is Level 2, so it already has a bit of margin against minor cryptanalytic improvements. ↩
-
Because SHA-256 is a better plug-in replacement for SHA-1, because SHA-1 was a much smaller surface than all of RSA and ECC, and because SHA-1 was not that broken: it still retained preimage resistance and could still be used in HMAC and HKDF. ↩
-
The delay was in large part due to my unfortunate decision of blocking on the availability of HPKE hybrid recipients, which blocked on the CFRG, which took almost two years to select a stable label string for X-Wing (January 2024) with ML-KEM (August 2024), despite making precisely no changes to the designs. The IETF should have an internal post-mortem on this, but I doubt we’ll see one. ↩
One point in favor of the sprawling Linux ecosystem is its broad hardware support—the kernel officially supports everything from '90s-era PC hardware to Arm-based Apple Silicon chips, thanks to decades of combined effort from hardware manufacturers and motivated community members.
But nothing can last forever, and for a few years now, Linux maintainers (including Linus Torvalds) have been pushing to drop kernel support for Intel's 80486 processor. This chip was originally introduced in 1989, was replaced by the first Intel Pentium in 1993, and was fully discontinued in 2007. Code commits suggest that Linux kernel version 7.1 will be the first to follow through, making it impossible to build a version of the kernel that will support the 486; Phoronix says that additional kernel changes to remove 486-related code will follow in subsequent kernel versions.
Although these chips haven't changed in decades, maintaining support for them in modern software isn't free.
"In the x86 architecture we have various complicated hardware emulation facilities on x86-32 to support ancient 32-bit CPUs that very, very few people are using with modern kernels," writes Linux kernel contributor Ingo Molnar in his initial patch removing 486 support from the kernel. "This compatibility glue is sometimes even causing problems that people spend time to resolve, which time could be spent on other things."
This echoes comments from Linus Torvalds in 2022, suggesting there was "zero real reason for anybody to waste one second of development effort" on 486-related problems. The removal of 486 support would also likely affect a handful of 486-compatible chips from other companies, including the Cyrix 5x86 and the Am5x86 from AMD. Molnar was also a driving force the last time Linux dropped support for an older Intel chip—support for the 80386 processor family was removed in kernel version 3.8 back in early 2013.
"Unfortunately there's a nostalgic cost: your old original 386 DX33 system from early 1991 won't be able to boot modern Linux kernels anymore," Molnar wrote. "Sniff."
A tree falling in a forest
The practical impact of the end of 486 support will be negligible; the number of modern Linux distributions that use the kernel's 486 support is negligible.
Many of the consumer-focused Linux distros have more Windows-like minimum system requirements, an acknowledgment of how CPU and RAM-intensive modern web browsers and browser-based apps have become; Ubuntu raised its minimum RAM requirement from 4GB to 6GB for the 26.04 LTS release. Even lightweight distros like Xubuntu or AntiX recommend 512MB to 1GB of RAM, amounts far in excess of what any 486-based PC ever shipped with (or could reasonably work with, using actual hardware).
One of the few actively maintained distros that explicitly mentions 486 support is Tiny Core Linux (and its GUI-less counterpart, Micro Core Linux). These OSes can run on a 486DX chip as long as it's paired with at least 48MB or 28MB of RAM, respectively, though a Pentium 2 with at least 128MB of RAM is the recommended configuration. But even on the Tiny Core forums, few users are mourning the loss of 486 support.
"I get the nostalgia, like classic cars, but a car you've spent a year's worth of weekends fixing up isn't a daily driver," writes user andyj. "Some of the extensions I maintain, like rsyslog and mariadb, require that the CPU be set to i586 as they will no longer compile for i486. The end is already here."
Those still using a 486 for one reason or another will still be able to run older Linux kernels and vintage operating systems—running old software without emulation or virtualization is one of the few reasons to keep booting up hardware this old. If you demand an actively maintained OS, you still have options, though—the FreeDOS project isn't Linux, but it does still run on PCs going all the way back to the original IBM Personal Computer and its 16-bit Intel 8088.

Bend, Oregon

Social network Bluesky saw some intermittent service disruptions on Monday. On its own, this fact isn't that noteworthy—Bluesky has seen similar service disruptions in the past, and this one coincided with widespread service problems being reported with other popular sites (Bluesky officially blamed the temporary problems on an "upstream service provider").
What made this outage notable for many Bluesky users, though, was the instant assumption that it was the result of sloppy, AI-assisted "vibe coding" by the Bluesky development team.
Amid Monday's service issues, many Bluesky feeds were filled with hundreds of posts that laid the blame on developers who were allegedly relying on unreliable AI tools to ship faulty code. Some used memes, others used alt text, still others used irony or wry humor to call out Bluesky's development team for this alleged sloppiness.
Overall, though, the mood among these vibe-code blamers was one of righteous anger. "Any developer or programmer using 'vibe-coding' or any reliance on AI to code things is clearly too stupid to know how to do the job they're paid to do and should be fired out of a cannon," Bluesky user T-Kay wrote, summing up the, er, vibe. "Coding takes skill, not slop."
bluesky employees: we are vibe coding the entire website using only AI now
yeah dude, i can tell
— lex luddy (ichiban appreciator) (@lexluddy.xyz) April 6, 2026 at 10:29 AM
It's the kind of reaction that highlights just how many tech users are still reflexively repulsed by the idea that AI tools were used in any way to create the products they use. Even as professional coders are becoming increasingly enthusiastic about the power of AI coding tools, many end users still see them as a boogeyman to instantly blame for any and all observed ills in the tech industry.
"Things are changing. Fast."
Before yesterday's outage, many on the Bluesky development team faced social media backlash for admitting they used AI tools in their work. Bluesky founder and Chief Innovation Officer Jay Graber posted point-blank in late March that "Bluesky is made with AI, the engineers and even some non-engineers use Claude Code," for instance. And Bluesky Technical Advisor Jeromy Johnson (who goes by the handle "Why" on the site) has been an outspoken proponent of AI coding tools, saying in February that "In the past two months Claude has written about 99% of my code. Things are changing. Fast."
Bluesky CTO Paul Frazee later joined in with a (perhaps joking) reply to Johnson saying, "I vibecode at least as much." Later, Frazee said that he saw a "call to action... for all of us to start utilizing this [AI] tech in our work."
Public worries about AI tools "infecting" the Bluesky experience increased on March 28 when the company announced Attie, a side project that lets users build their own custom Bluesky feed by talking to a chatbot built on Claude Code. Bluesky team members said the tool's eventual goal, as reported by TechCrunch, was to let users vibe-code their own social apps.
Until December of last year I was using LLMs as fancy autocomplete for coding. It was nice for scaffolding out boilerplate, or giving me a gut check on some things, or banging out some boring routine stuff.
In the past two months Claude has written about 99% of my code. Things are changing. Fast
While Attie is a separate product that is not part of the core Bluesky app, many AI skeptics in the Bluesky user base were still disgusted by what they saw as a worrying developer distraction at best and an unwelcome AI integration at worst. That was especially true given that Bluesky attracted many users from Elon Musk's Grok-ified X with a 2024 promise not to use Bluesky posts to train any AI models.
"We hear the concerns about AI," Graber posted last week in response to the uproar around Attie. "Our goal is to use this technology to give people greater control, not to generate content. Attie uses AI to help you create custom feeds without having to know how to code."
These worries over AI coding and side projects had been marinating among the most anti-AI segments of the Bluesky user base for weeks before yesterday's service disruptions. Given that setup, many seemed eager to jump to the conclusion that Bluesky's issues must be connected to AI use among its coders, relishing the presumption with a clear sense of "this is what you get" schadenfreude.
This isn't the only recent example of "vibe coding" being blamed for a tech snafu. When Anthropic accidentally leaked its client source code last week, some social media users similarly assumed it was the result of a sloppy vibe coder making a mistake while using Claude Code to push the release. While Anthropic's Boris Cherny blamed the leak on human error during the code's manual deploy process, that hasn't stopped some from trying to tie the blunder to Cherny's admission that the team relies on Claude Code to create "pretty much 100% of our code."
Is it "vibe coding" or mere "AI-assistance"?
Potential leaks aside, the last year has given plenty of ammo to tech watchers predisposed to skepticism toward vibe coding. Sloppy AI coding assistance was blamed for a recent six-hour outage at Amazon, and in multiple recent stories of rogue coding agents irretrievably deleting files against human coders' wishes. Then there are the well-founded worries about the security risks of vibe-coded software, and the many examples of vibe-coded projects that are unbearably buggy or unreliable.
But glitchy software and Internet service problems existed long before vibe coding was a thing, of course. Instantly attributing any software or service glitch you see to the scourge of AI-generated code, without evidence, is as presumptuous as assuming that AI demonstrates perfect reasoning.
On a personal level, I've been a software engineer since I was 12. I joke about the quality of my code, but the reality is that I take it incredibly seriously. The source of those jokes is humility to how difficult it is to write complex software and avoid bugs, or outages.
— Paul Frazee (@pfrazee.com) March 5, 2026 at 4:58 PM
Putting all code made with AI assistance into the same mental "vibe-coded slop" bucket can also obscure some important distinctions in how these tools are used. The original definition of "vibe coding," as it was coined over a year ago, described amateurs and non-coders using AI to generate minimally working but extremely brittle code without understanding how it works. That's completely different from experienced developers using AI-powered coding tools to program more efficiently while still using their accumulated coding knowledge to organize, check, and verify the code. As we wrote in a January hands-on deep dive into the bowels of AI coding tools, "even with the best AI coding agents available today, humans remain essential to the software development process."
Frazee tried to highlight this distinction in an early March thread, clarifying how Bluesky developers use AI behind the scenes. "The Bluesky team maintains the same review, red-teaming, and QA processes that we always have," Frazee wrote. "AI coding tools have been proving useful, but haven't changed the fundamental practices of good engineering. Human review and direction remain key."
That distinction has seemed to resonate with some Bluesky users, who have urged restraint for those eager to blame every service glitch on AI code. "There's an actual conversation to be had about AI-assisted coding and being a software developer that architects more complex systems, and where AI can be incredibly useful," Bluesky user Randi Lee Harper wrote. "But it's impossible to have that conversation when folks not in tech jump in saying 'AI is bad, always.'"
But even some who understand that Bluesky hasn't suddenly been converted into 100 percent vibe-coded slop were happy for an opportunity to mock developers for using AI tools in the first place. "Is blaming vibe coding for the Bluesky outage plainly wrong? Yes," Bluesky user Lucyfer wrote. "Is it funny? Also yes."
In other words, even if vibe coding is merely a public boogeyman for many software glitches, it's one that coders may have to get used to hearing about if they admit to using AI tools at all. "The lesson from today’s downtime isn’t that it was caused by vibe coding..." Bluesky user Dalton Deschain wrote. "It’s that if you use AI you will no longer get the benefit of the doubt and everyone will mock you for laziness regardless of the cause."

Conversely to all the whiners about it, I'd say any engineers too stupid to know how to leverage LLMs to boost their own work will soon be looking for employment
Bend, Oregon
LG was once a heavyweight in the smartphone industry, trading blows with hometown rival Samsung. However, as smartphone sales plateaued, the company struggled to stay competitive. In 2021, LG planned to make waves with a rollable phone, but it never moved beyond the teaser phase. Five years after LG threw in the towel on smartphones, the LG Rollable has appeared in a YouTube teardown that demonstrates why this form factor never took off.
The LG Rollable is just one of several rollable concept phones that appeared throughout the early 2020s. Flexible OLED screens had finally become affordable, leading to foldable phones like the Samsung Galaxy Z Fold. Although, "affordable" is relative here. Foldables were and still are very expensive devices. Based on what we can see of the complex inner workings of the LG Rollable, these devices may have commanded even higher prices.
Noted YouTube phone destroyer JerryRigEverything managed to snag a working prototype LG Rollable. It may even be the unit LG demoed at CES 2021. The device looks like a regular phone at first glance, but a quick swipe activates the motor, which unfurls additional screen real estate from around the back. This makes the viewable area about 40 percent larger without the added thickness of a foldable.
LG Rollable teardown
The device expands with the aid of two tiny motors, which are attached via straight teeth to an internal track. The screen assembly has zipper-like teeth that keep it locked into the frame as it moves. The motors make a surprising amount of noise when operating, so LG designed the phone to play a musical chime to hide the sound.
While the motor does the heavy lifting, the phone also has a lattice of articulating spring-loaded arms inside that keep the OLED panel even as the frame slides side to side. The battery and motherboard sit in a tray that allows the back of the phone to expand as the OLED rolls into view.
This is a prototype phone, featuring a chunky frame and visible screws. That helped Zack Nelson from JerryRigEverything successfully disassemble and reassemble the phone. So this little bit of mobile history was not destroyed, and the teardown gives us a good look at how LG was hoping to attract new customers before calling it quits.
LG's last gasp
In 2020, LG's mobile division was searching for a way to stand out. The company tried hand gestures, rotating screens, phone cases with secondary screens, and rehashing old hardware with more stylish exteriors—none of it worked. Maybe the Rollable would have stood out if it launched in 2021 as planned, but looking at how it's built, it's hard to see how it could have been a successful product.
There's no doubt this piece of hardware is very cool. It's overengineered to an impressive degree, particularly for LG. That may sound like a dig, but it's not! This device demonstrates the kind of 2020 engineering chops we'd expect from the likes of Samsung. It doesn't look like something designed by a company that was mere months away from killing its smartphone division.
 The rollable uses two motors on a geared track to expand the frame.
Credit:
JerryRigEverything
The rollable uses two motors on a geared track to expand the frame.
Credit:
JerryRigEverything
Okay, but there are problems with that kind of engineering. The complexity of the internals would have made the Rollable extremely expensive to manufacture, and it would have demanded a high price tag. Asking people to pay Galaxy Z money for an LG phone in 2021 was probably a non-starter.
Durability is also a big concern. There's just a lot going on inside this phone, with multiple motors, springy arms, tracks, and a screen that has to loop around the back. Even unpowered hinges on foldable phones add an additional point of failure, and they do fail sometimes. It took Samsung a few tries to design a hinge that wouldn't be defeated by dust, and a motorized phone would be even more vulnerable. It seems unlikely the LG Rollable could have survived daily use for multiple years.
As neat as this phone looks, no one ever pursued the form factor. LG wasn't alone in demoing rollables back then. Motorola, Oppo, and others showed off similar hardware at press events and trade shows, presenting the rollable as the next evolution of foldables. Still, no one has released a rollable even as foldables continue to chug along. Were they too fragile? Too expensive? Too loud? Maybe it was a mix of all of the above, based on what we've now seen of the LG Rollable. Manufacturing this phone at scale would have been a major undertaking, so it's not too surprising that LG just gave up rather than risk it.
Because LG never launched the Rollable, the Wing with its weird rotating screen went down in history as the company's final smartphone release.

Bend, Oregon
Next Page of Stories